
비용·저작권 리스크 줄이고 보안성 높일 수 있어
한국 스타트업, 미국 빅테크와 경쟁 직면
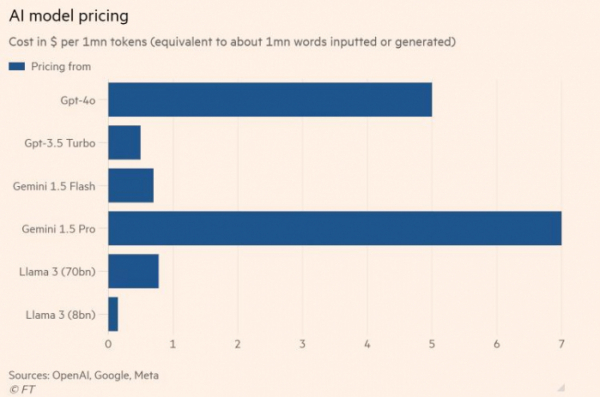
‘거대언어모델(LLM)’ 구축에 열을 올렸던 미국 빅테크들이 인공지능(AI) 수익창출 수단으로는 ‘소형언어모델(SLM)’에 주목하고 있다.
18일(현지시간) 영국 파이낸셜타임스(FT)는 마이크로소프트(MS), 페이스북 모회사 메타플랫폼, 구글 등 빅테크들이 최근 LLM 최신 버전과 함께 경량화 버전인 SLM을 동시에 선보이고 있다며 이같이 보도했다.
메타는 지난달 최신 AI 모델 ‘라마3’를 ‘매개변수(파라미터)’가 700억 개인 모델과 80억 개인 소형 모델 등 두 가지로 선보였다. 구글도 14일 자사 생성형 AI의 최신 버전인 ‘제미나이 1.5 프로’를 공개하면서 이보다 더 가벼우면서도 멀티모달 추론과 긴 텍스트 작성이 가능한 ‘제미나이 1.5 플래시’도 선보였다.
지난주 오픈AI가 발표한 최신 모델 ‘GPT-4o’와 구글의 ‘제미나이 1.5프로’ 등 각사를 대표하는 생성형 AI는 모두 매개변수가 1조 개 이상으로 알려졌다.
하지만 언어모델의 덩치가 커지면 비용 부담은 물론 저작권에 대한 리스크도 커지게 된다. FT에 따르면 제미나이 1.5프로의 경우 ‘100만 토큰(AI가 한 번에 처리할 수 있는 데이터 단위)’당 단위 비용이 7달러에 달한다. 오픈AI의 GTP-4o는 5달러가 든다. 반면 SLM으로 꼽히는 GPT-3.5터보, 제미나이 1.5플래시, 메타의 라마3 등은 모두 100만 토큰당 비용이 1달러 미만이다.
이에 빅테크들은 고객사들이 가성비 측면에서 접근할 수 있도록 매개변수를 줄인 SLM을 통해 수익을 내겠다는 전략을 펼치고 있다고 FT는 설명했다.
SLM은 매개변수가 적어 연산 작업이 단축된 만큼 답을 얻는 시간도 짧고, 크기가 작아 클라우드를 거치지 않고 사내 시스템 내 설치가 가능하다는 장점도 있다. 즉 에너지 효율성이 LLM에 비해 높고 보안성도 높다는 이야기다.
성능도 LLM 못지않다. 메타는 80억 매개변수의 라마3 성능이 GPT-4와 비슷하다고 주장하고 있다. MS는 70억 개의 매개변수를 가진 SLM ‘파이(Phi)-3’가 GPT-3.5보다 성능이 뛰어나다고 밝혔다.
업계에서는 기기에 설치돼 인터넷에 연결되지 않아도 활용이 가능한 온디바이스 AI의 수요 증가로 SLM이 더욱 주목받을 것으로 보고 있다. 실제로 삼성전자의 갤럭시 S24에 탑재된 AI는 구글의 ‘제미나이 나노’다.
다만 일각에서는 우리나라 AI 스타트업들이 ‘틈새시장’으로 ‘도메인(산업 분야) 특화 SLM’에 주력하고 있는 상황에서 이들 빅테크의 행보가 우리나라 기업들의 전략에도 영향을 줄 수 있다는 지적이 나온다.
인간 두뇌의 시냅스처럼 생성형 AI에서 각각의 부분을 연결하는 것을 매개변수(파라미터)라고 하는데, 이 매개변수가 1000억 개 이상이면 LLM, 그 미만이면 SLM으로 분류한다.









![[찐코노미] ‘D-1’ 美 대선, 초박빙…글로벌 금융시장도 긴장](https://img.etoday.co.kr/crop/320/200/2097489.jpg)